")
")
vocab-express
So far, Linked Data principles and practices are being adopted by an increasing number of data providers, getting as result a global data space on the Web containing hundreds of LOD datasets. In this context it is important to promote the reuse and linkage of datasets, and to this end, it is necessary to know the structure of datasets. One step forward for knowing in depth the structure of a given dataset is to explore the vocabulary used in the dataset, and how the dataset is actually using such vocabulary.
vocab-express a simple tool for exploring the vocabulary used in a given dataset. The tool provides all the related information of the vocabulary:
- the list of all classes
- the list of all the properties
- the number of instances of each class
- the number instances of each property
- the language of labels and comments of the vocabulary elements
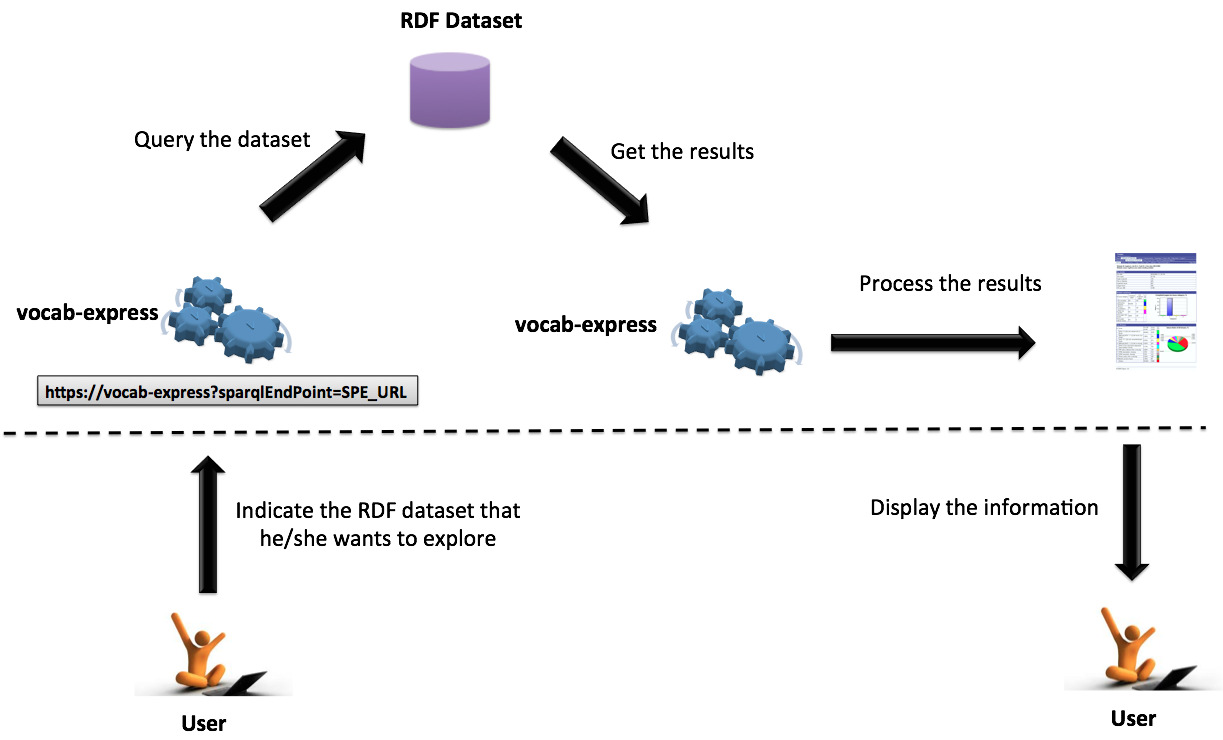
vocab-express is being implemented in node.js, which is a platform built on V8 (Google's open source JavaScript engine) for easily building fast, scalable network applications. The figure below depicts the workflow of vocab-express. Next we describe the steps of the workflow:
- The user indicates the RDF dataset he/she wants to explore by providing its SPARQL endpoint URL
- vocab-express receives and validates the SPARQL endpoint URL
- vocab-express queries the SPARQL endpoint and gets results
- vocab-express processes the results and displays the information to the user